A vision-language model that unifies vision-language understanding and generation tasks.
主要分为两块工作:
- 去除图文检索所使用的数据集中的噪声
- vision language understanding and generation
Model
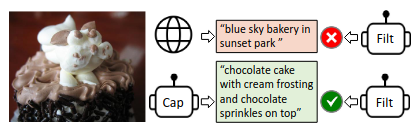
Noise Filtering
Caption 模型生成图像文本对,然后Filt将caption和真实互联网数据(可能存在噪声)进行对比,如果差异过大则使用Caption模型生成的结果
Understanding & Generation